Machine Learning
Machine learning workflows we use.
We use two different models to process videos and extract topics and subtopics for each second of the video.
CLIP
CLIP (Contrastive Langauge-Image Pre-training) builds on a large body of work on zero-shot transfer, natural language supervision, and multimodal learning. CLIP uses a vision transformer to extract visual features from an image, and a causal language model to extract textual features from a list of potential captions or tags (topics). It them maps the two feature vectors to the same space, and computes the probability of the caption or topic being relevant to the image.
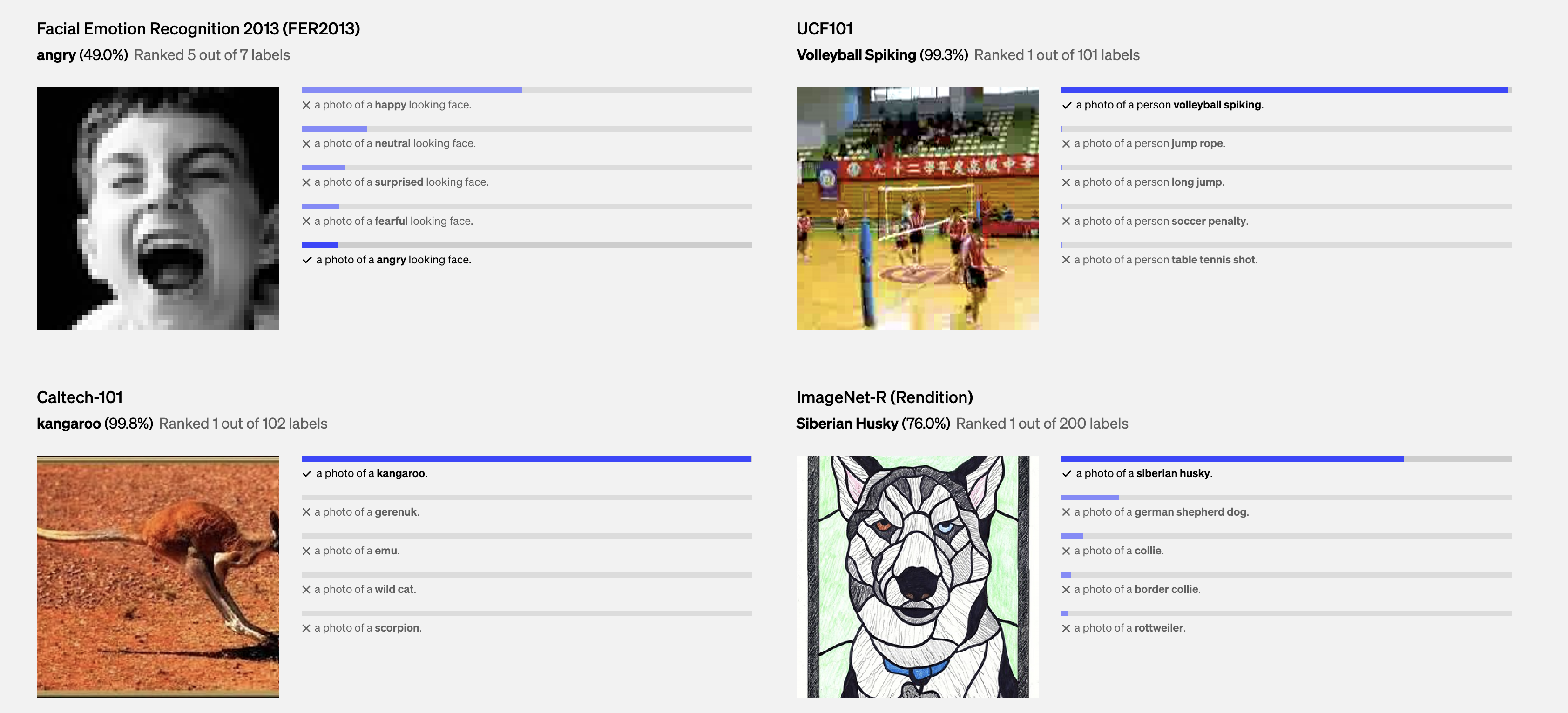
The CLIP model was first proposed by OpenAI in January 2021.
BART
BART (Bidirectional and Auto-Regressive Transformers) is a denoising sequence-to-sequence model for natural language generation, translation, and comprehension.
It considers an input sequence and bi-directionally analyzes the meaning of each word in context to generate a latent representation of the input sequence.
In our case, we ue bart for zero-shot classification, where the input sequence is transcript data around a given second, and it outputs the probability of each topic being relevant to that input sequence.
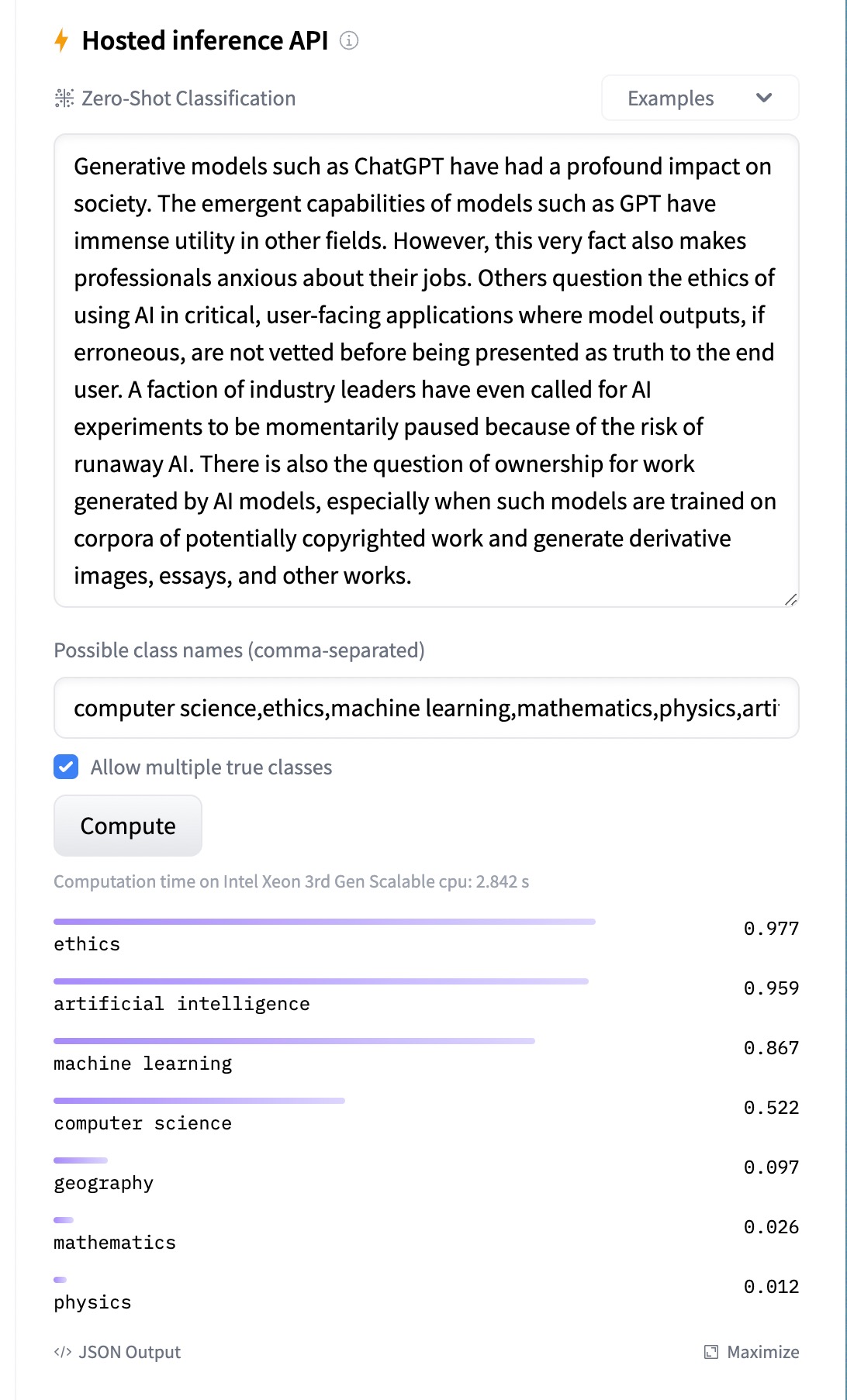
The BART model was first proposed by Facebook AI in October 2019.
The next step is sectioning the video into segments based on the topics.